My First Model#
[1]:
# Load autoreload extension for development convenience
%load_ext autoreload
%autoreload 2
![]()
This guide will walk you through creating and training your first simulation-based inference model using GenSBI. We will cover the essential steps, from defining a simulator to training a neural density estimator.
As a frist step, make sure gensbi is installed in your environment. If you haven’t done so yet, please refer to the Installation Guide before proceeding, or simply run:
[2]:
# step 1: install packages
# %pip install "GenSBI[cuda12,examples,validation] @ git+https://github.com/aurelio-amerio/GenSBI.git" --extra-index-url https://download.pytorch.org/whl/cpu
Important: If you are using Colab, restart the runtime after installation to ensure all packages are properly loaded.
Next it is convenient to download the GenSBI-examples package, which contains several example notebooks and checkpoints, including this one. You can do so by running:
[3]:
# step 2: clone the examples repository
# !git clone --depth 1 https://github.com/aurelio-amerio/GenSBI-examples.git
[4]:
# step 3: cd into the examples folder
# %cd GenSBI-examples
%cd /home/zaldivar/symlinks/aure/Github/GenSBI-examples/examples/getting_started/GenSBI-examples
/home/zaldivar/Documents/Aurelio/Github/GenSBI-examples/examples/getting_started/GenSBI-examples
Then we need to import all the necessary modules from GenSBI and other libraries. If you don’t have a gpu available, you can set the device to “cpu” instead of “cuda”, but training will be slower.
If you are getting some errors relating to missing packages, restart the notebook kernel, and run step 3 again.
[5]:
import os
# Set JAX backend (use 'cuda' for GPU, 'cpu' otherwise)
# os.environ["JAX_PLATFORMS"] = "cuda"
import grain
import numpy as np
import jax
from jax import numpy as jnp
from numpyro import distributions as dist
from flax import nnx
from gensbi.recipes import Flux1FlowPipeline
from gensbi.models import Flux1Params
from gensbi.utils.plotting import plot_marginals
import matplotlib.pyplot as plt
W0111 23:16:37.391252 3194236 cuda_executor.cc:1802] GPU interconnect information not available: INTERNAL: NVML doesn't support extracting fabric info or NVLink is not used by the device.
W0111 23:16:37.397042 3194096 cuda_executor.cc:1802] GPU interconnect information not available: INTERNAL: NVML doesn't support extracting fabric info or NVLink is not used by the device.
The simulator#
The first step in simulation-based inference is to define a simulator function that generates data given parameters. In this example, we will create a simple simulator that generates data from a Gaussian distribution with a mean defined by the parameters.
The simulator takes in 3 parameters (theta) and returns 3 observations (xs).
In the context of posterior density estimation, the theta parameters are the observations (what we want to model) and the xs are the conditions (the data we condition on, which we use to detemrine theta).
[6]:
dim_obs = 3 # dimension of the observation (theta), that is the simulator input shape
dim_cond = 3 # dimension of the condition (xs), that is the simulator output shape
dim_joint = dim_obs + dim_cond # dimension of the joint (theta, xs), useful later
def _simulator(key, thetas):
xs = thetas + 1 + jax.random.normal(key, thetas.shape) * 0.1
thetas = thetas[..., None]
xs = xs[..., None]
# when making a dataset for the joint pipeline, thetas need to come first
data = jnp.concatenate([thetas, xs], axis=1)
return data
Now we define a prior distribution over the parameters. For simplicity, we will use a uniform prior over a specified range.
[7]:
theta_prior = dist.Uniform(
low=jnp.array([-2.0, -2.0, -2.0]), high=jnp.array([2.0, 2.0, 2.0])
)
For simpliciy, we define a simulator which samples from the prior internally.
[8]:
def simulator(key, nsamples):
theta_key, sample_key = jax.random.split(key, 2)
thetas = theta_prior.sample(theta_key, (nsamples,))
return _simulator(sample_key, thetas)
The dataset#
We create a dataset by running the simulator multiple times with parameters sampled from the prior distribution. This dataset will be used to train the neural density estimator.
GenSBI can work with any dataset that provides an iterator to obtain couples of (parameters, observations). For numerical efficiency and ease of use, it is convenient to create a Jax-based datset using grain, for high efficiency data-loading and prefetching.
[9]:
# Define your training and validation datasets.
train_data = simulator(jax.random.PRNGKey(0), 10_000)
val_data = simulator(jax.random.PRNGKey(1), 2000)
[10]:
# utility function to split data into observations and conditions
def split_obs_cond(data):
return data[:, :dim_obs], data[:, dim_obs:] # assuming first dim_obs are obs, last dim_cond are cond
We create a grain dataset with batch size = 128. The larger the batch size, the more stable the training.
Adjust according to your hardware capabilities, e.g. GPU memory (try experimenting with 256, 512, 1024, etc).
[11]:
batch_size = 256
train_dataset_grain = (
grain.MapDataset.source(np.array(train_data))
.shuffle(42)
.repeat()
.to_iter_dataset()
.batch(batch_size)
.map(split_obs_cond)
.mp_prefetch() # If you use prefetching in a .py script, make sure your python script is thread safe, see https://docs.python.org/3/library/multiprocessing.html
)
val_dataset_grain = (
grain.MapDataset.source(np.array(val_data))
.shuffle(42)
.repeat()
.to_iter_dataset()
.batch(batch_size)
.map(split_obs_cond)
.mp_prefetch()
)
These datasets are innfinite dataloaders, meaning that they will keep providing data as long as needed. You can get samples from the dataset using:
[12]:
iter_dataset = iter(train_dataset_grain)
obs,cond = next(iter_dataset) # returns a batch of (observations, conditions)
print(obs.shape, cond.shape) # should print (batch_size, dim_obs, 1), (batch_size, dim_cond, 1)
(256, 3, 1) (256, 3, 1)
The Model#
We define a Flux1 model and pipeline. Flux1 is a versatile transformer-based architecture suitable for various (complex) SBI tasks. Although for this problem a simpler architecture would suffice, we use Flux1 to illustrate how to set up the main components of a GenSBI model.
[13]:
# define the model parameters
params = Flux1Params(
in_channels=1, # each observation/condition feature has only one channel (the value itself)
vec_in_dim=None,
context_in_dim=1,
mlp_ratio=3, # default value
num_heads=2, # number of transformer heads
depth=4, # number of double-stream transformer blocks
depth_single_blocks=8, # number of single-stream transformer blocks
axes_dim=[ 10,], # number of features per transformer head
qkv_bias=True, # default
dim_obs=dim_obs, # dimension of the observation (theta)
dim_cond=dim_cond, # dimension of the condition (xs)
id_embedding_strategy=("absolute","absolute"),
rngs=nnx.Rngs(default=42), # random number generator seed
param_dtype=jnp.bfloat16, # data type of the model parameters. if bfloat16 is not available, use float32
)
For the sake of running this example, we will
[19]:
# checkpoint_dir = os.path.join(os.getcwd(), "examples/getting_started/checkpoints")
checkpoint_dir = "/home/zaldivar/symlinks/aure/Github/GenSBI-examples/examples/getting_started/checkpoints"
training_config = Flux1FlowPipeline.get_default_training_config()
training_config["checkpoint_dir"] = checkpoint_dir
training_config["experiment_id"] = 1
training_config["nsteps"] = 5_000
training_config["decay_transition"] = 0.90
training_config["warmup_steps"] = 500
Note: It is important to set the number of training steps (
nsteps) in the training config, as this will ensure warmup steps and decay transition are computed correctly.
[20]:
checkpoint_dir
[20]:
'/home/zaldivar/symlinks/aure/Github/GenSBI-examples/examples/getting_started/checkpoints'
[21]:
# Intantiate the pipeline
pipeline = Flux1FlowPipeline(
train_dataset_grain,
val_dataset_grain,
dim_obs,
dim_cond,
params=params,
training_config=training_config,
)
Training#
Now we train the model using the defined pipeline. We specify the number of epochs and the random seed for reproducibility.
[22]:
rngs = nnx.Rngs(42)
[23]:
# uncomment to train the model
loss_history = pipeline.train(
rngs, save_model=True
) # if you want to save the model, set save_model=True
100%|██████████| 5000/5000 [19:17<00:00, 4.32it/s, counter=0, loss=0.1557, ratio=1.0042, val_loss=0.1464]
Saved model to checkpoint
If you don’t want to waste time retraining the model, you can directly load a pre-trained model for this example using this code:
[24]:
# pipeline.restore_model(1)
Sampling from the posterior#
In order to sample from the posterior distribution given new observations, we use the trained model’s sample method. We provide the observation for which we want to reconstruct the posterior, and specify the number of samples we want to draw from the posterior.
[53]:
new_sample = simulator(jax.random.PRNGKey(20), 1) # the observation for which we want to reconstruct the posterior
true_theta = new_sample[:, :dim_obs, :] # The input used for the simulation, AKA the true value
x_o = new_sample[:, dim_obs:, :] # The observation from the simulation for which we want to reconstruct the posterior
Now we sample from the posterior:
[54]:
samples = pipeline.sample(rngs.sample(), x_o, nsamples=100_000)
Once we have the samples, we display the marginal distributions:
[55]:
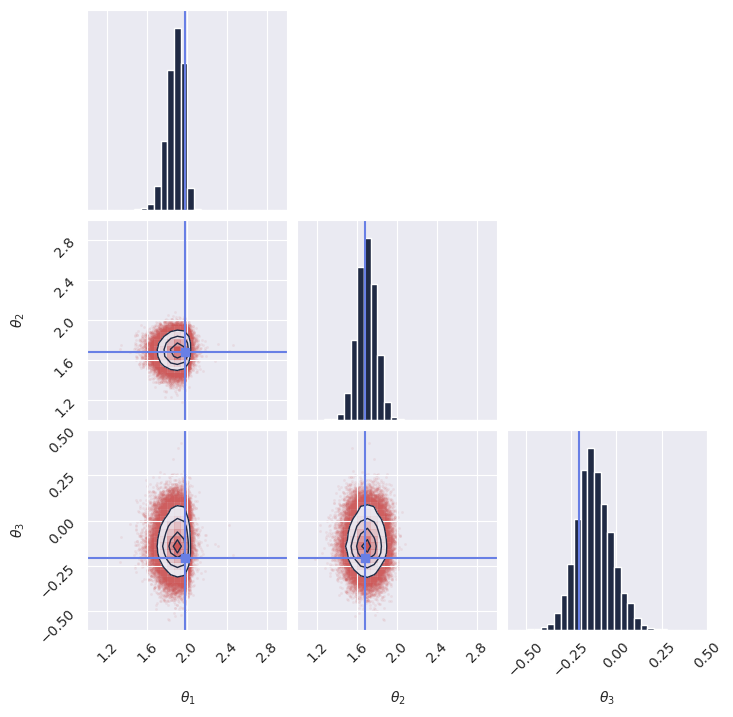
plot_marginals(
np.array(samples[..., 0]), gridsize=30, true_param=np.array(true_theta[0, :, 0]), range = [(1, 3), (1, 3), (-0.6, 0.5)]
)
# plt.savefig("flux1_flow_pipeline_marginals.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
<Figure size 640x480 with 0 Axes>
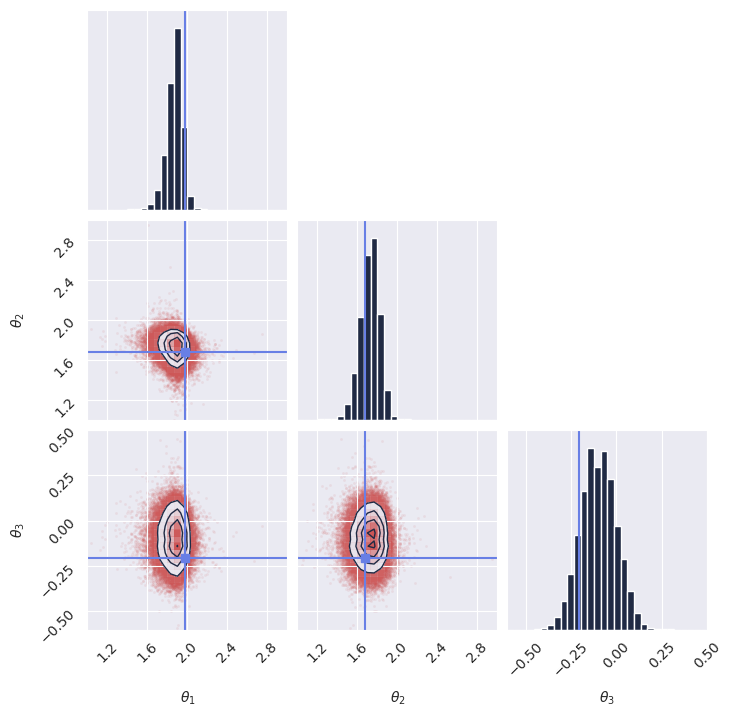
Next steps#
Congratulations! You have successfully created and trained your first simulation-based inference model using GenSBI. You can now experiment with different simulators, priors, and neural density estimators to explore more complex inference tasks.
For more examples, please refer to the Examples Section of the GenSBI documentation.
As a step forward, you might want to explore how to validate the performance of your trained model using techniques such as simulation-based calibration (SBC) or coverage plots. These methods help assess the quality of the inferred posterior distributions and ensure that your model is providing accurate uncertainty estimates.
Posterior calibration tests#
In this section we perform posterior calibration tests using Simulation-Based Calibration (SBC), Targeted At Random Parameters (TARP) and L-C2ST methods to evaluate the quality of our trained model’s posterior estimates.
For a full overiew of posterior calibration tests, refer to the sbi documentation.
[28]:
# imports
from gensbi.diagnostics import check_tarp, run_tarp, plot_tarp
from gensbi.diagnostics import check_sbc, run_sbc, sbc_rank_plot
from gensbi.diagnostics import LC2ST, plot_lc2st
We sample 200 new observations from the simulator to perform the calibration tests. It is instrumental that we use a seed different from the one used during training to avoid biased results.
[29]:
key = jax.random.PRNGKey(1234)
# sample the dataset
test_data = simulator(jax.random.PRNGKey(1), 200)
# split in thetas and xs
thetas_ = test_data[:, :dim_obs, :] # (200, 3, 1)
xs_ = test_data[:, dim_obs:, :] # (200, 3, 1)
[30]:
# sample the posterior for each observation in xs_
posterior_samples_ = pipeline.sample_batched(jax.random.PRNGKey(0), xs_, nsamples=1000) # (1000, 200, 3, 1)
Sampling: 100%|██████████| 20/20 [05:34<00:00, 16.75s/it]
For the sake of posterior calibration tests, the last two dimensions need to be joined together.
[31]:
thetas = thetas_.reshape(thetas_.shape[0], -1) # (200, 3)
xs = xs_.reshape(xs_.shape[0], -1) # (200, 3)
posterior_samples = posterior_samples_.reshape(posterior_samples_.shape[0], posterior_samples_.shape[1], -1) # (1000, 200, 3)
SBC#
SBC allows you to evaluate whether individual marginals of the posterior are, on average across many observations (prior predictive samples) too narrow, too wide, or skewed.
[33]:
ranks, dap_samples = run_sbc(thetas, xs, posterior_samples)
check_stats = check_sbc(ranks, thetas, dap_samples, 1_000)
Calculating ranks for 200 SBC samples: 0%| | 0/200 [00:00<?, ?it/s]Calculating ranks for 200 SBC samples: 100%|██████████| 200/200 [00:01<00:00, 112.93it/s]
[34]:
print(check_stats)
{'ks_pvals': Array([0.00049511, 0.02252806, 0.02252806], dtype=float32), 'c2st_ranks': array([0.505 , 0.46250001, 0.4725 ]), 'c2st_dap': Array([0.4875 , 0.45250002, 0.51500005], dtype=float32)}
[35]:
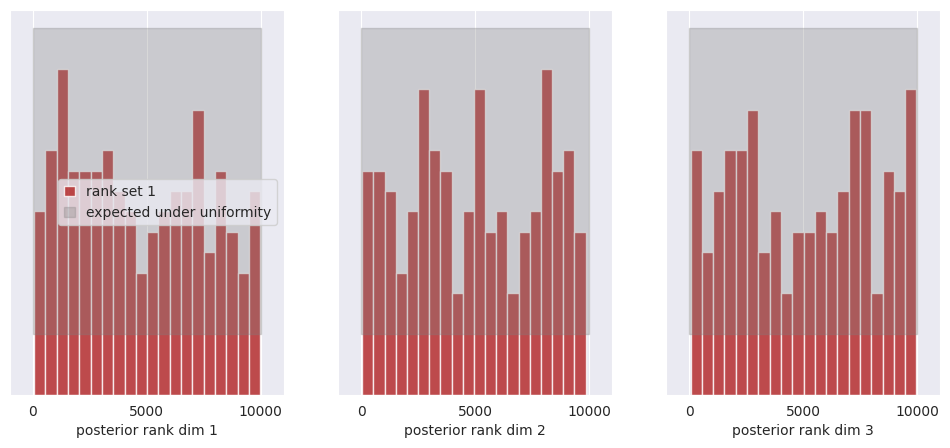
f, ax = sbc_rank_plot(ranks, 1_000, plot_type="hist", num_bins=20)
plt.savefig("flux1_flow_pipeline_sbc.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
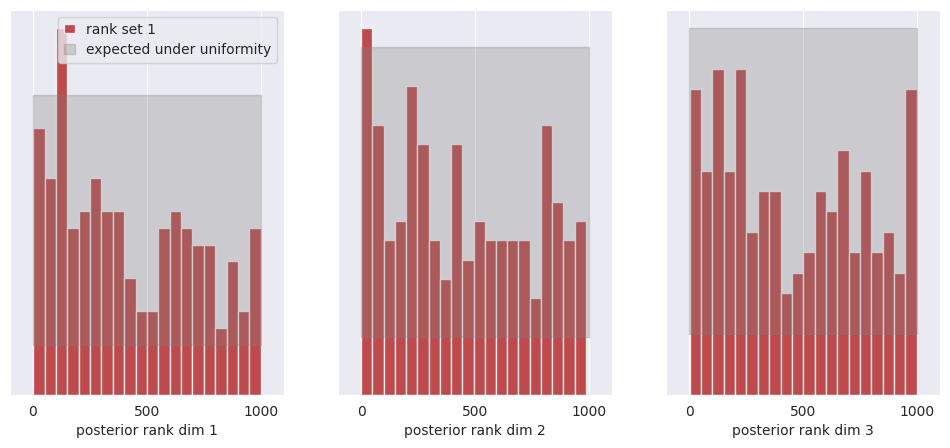
All of the bars fall within the expected uniform distribution, thus we cannot reject the hypothesis that the posterior marginals are calibrated.
See the SBI tutorial https://sbi.readthedocs.io/en/latest/how_to_guide/16_sbc.html for more details on SBC.
TARP#
TARP is an alternative calibration check proposed recently in https://arxiv.org/abs/2302.03026.
[36]:
ecp, alpha = run_tarp(
thetas,
posterior_samples,
references=None, # will be calculated automatically.
)
[37]:
atc, ks_pval = check_tarp(ecp, alpha)
print(atc, "Should be close to 0")
print(ks_pval, "Should be larger than 0.05")
0.346998929977417 Should be close to 0
0.999115261755522 Should be larger than 0.05
[38]:
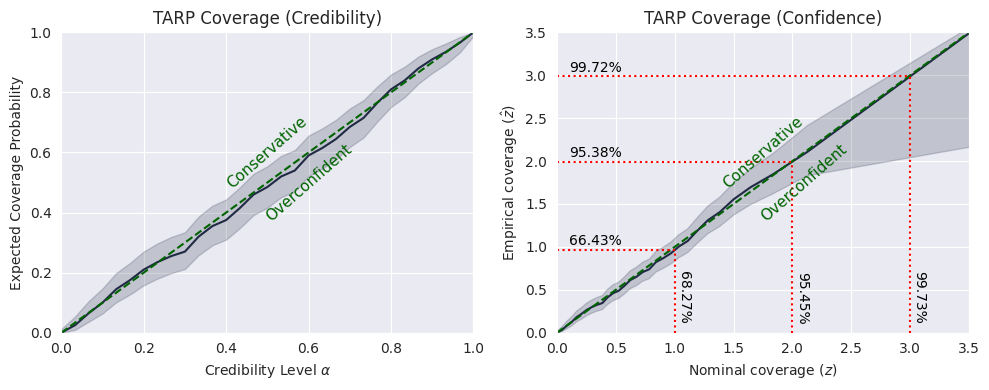
plot_tarp(ecp, alpha)
plt.savefig("flux1_flow_pipeline_tarp.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
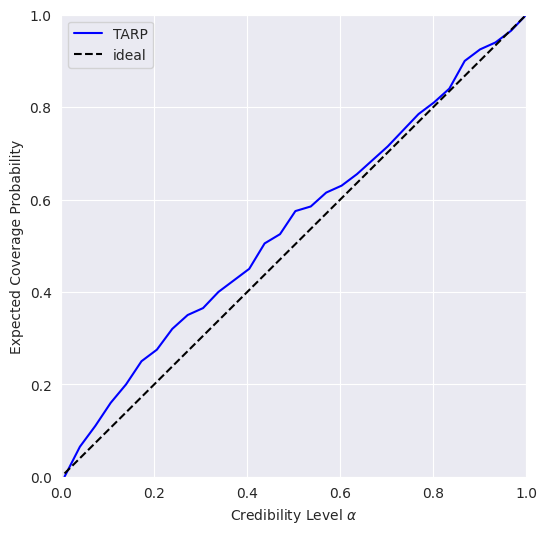
If the blue curve is above the diagonal, then the posterior estimate is under-confident. If it is under the diagonal, then the posterior estimate is over confident.
This means that our model is slightly under-confident.
See https://sbi.readthedocs.io/en/latest/how_to_guide/17_tarp.html for more details on TARP.
L-C2ST#
Tests like expected coverage and simulation-based calibration evaluate whether the posterior is on average across many observations well-calibrated. Unlike these tools, L-C2ST allows you to evaluate whether the posterior is correct for a specific observation.
[39]:
# Simulate calibration data. Should be at least in the thousands.
key = jax.random.PRNGKey(1234)
# sample the dataset
test_data = simulator(jax.random.PRNGKey(1), 10_000)
# split in thetas and xs
thetas_ = test_data[:, :dim_obs, :] # (10_000, 3, 1)
xs_ = test_data[:, dim_obs:, :] # (10_000, 3, 1)
[40]:
# Generate one posterior sample for ev_ery prior predictive.
posterior_samples_ = pipeline.sample(key, x_o=xs_, nsamples=xs_.shape[0])
[41]:
thetas = thetas_.reshape(thetas_.shape[0], -1) # (10_000, 3)
xs = xs_.reshape(xs_.shape[0], -1) # (10_000, 3)
posterior_samples = posterior_samples_.reshape(posterior_samples_.shape[0], -1) # (10_000, 3)
[42]:
from gensbi.diagnostics import LC2ST, plot_lc2st
# Train the L-C2ST classifier.
lc2st = LC2ST(
thetas=thetas,
xs=xs,
posterior_samples=posterior_samples,
classifier="mlp",
num_ensemble=1,
)
[43]:
_ = lc2st.train_under_null_hypothesis()
Training the classifiers under H0, permutation = True: 0%| | 0/100 [00:00<?, ?it/s]Training the classifiers under H0, permutation = True: 100%|██████████| 100/100 [07:05<00:00, 4.25s/it]
[44]:
_ = lc2st.train_on_observed_data()
[45]:
key = jax.random.PRNGKey(12345)
sample = simulator(key, 1)
# theta_true_ = sample[:, :dim_obs, :]
x_o_ = sample[:, dim_obs:, :]
# Note: x_o must have a batch-dimension. I.e. `x_o.shape == (1, observation_shape)`.
post_samples_star_ = pipeline.sample(key, x_o_, nsamples=10_000)
[46]:
# theta_true = theta_true_.reshape(-1) # (3,)
x_o = x_o_.reshape(1,-1) # (3,)
post_samples_star = np.array(post_samples_star_.reshape(post_samples_star_.shape[0], -1)) # (10_000, 3)
[47]:
post_samples_star.shape, x_o.shape
[47]:
((10000, 3), (1, 3))
[48]:
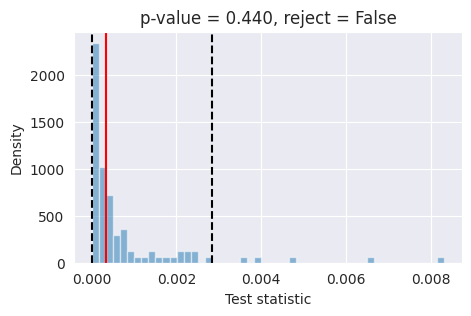
fig,ax = plot_lc2st(
lc2st,
post_samples_star,
x_o,
)
plt.savefig("flux1_flow_pipeline_lc2st.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
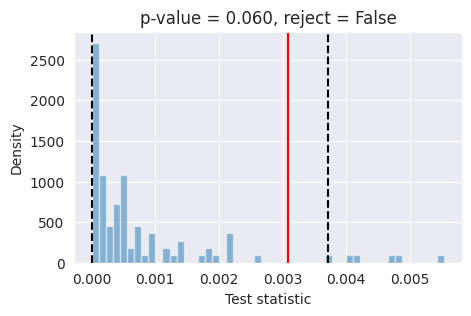
If the red bar falls outside the two dashed black lines, it indicates that the model’s posterior estimates are not well-calibrated at the 95% confidence level and further investigation is required.
Conclusions#
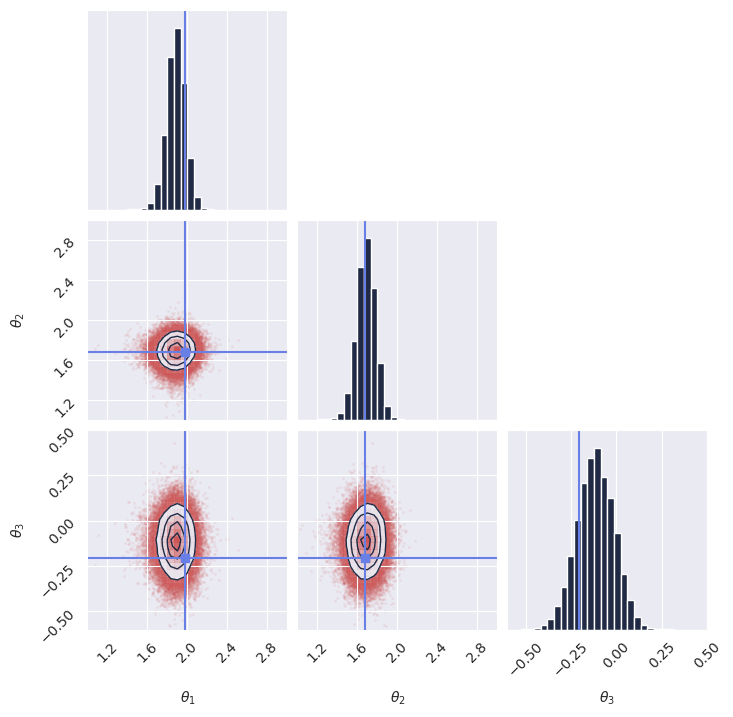
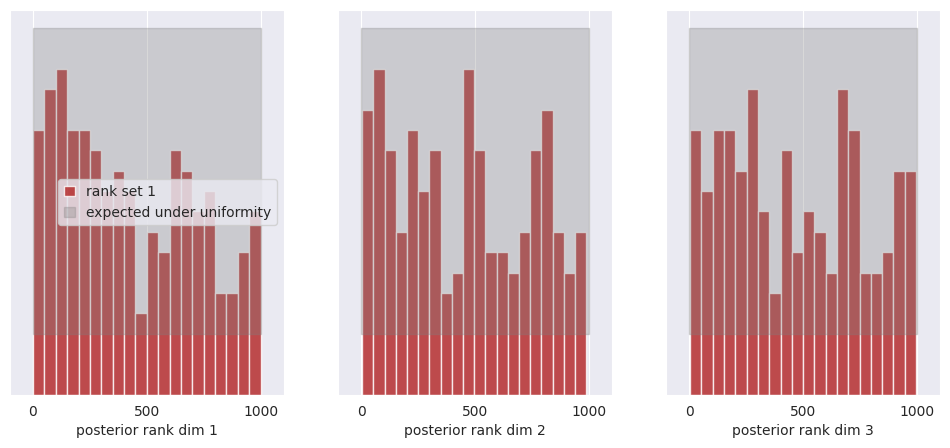
What happened? As it turns out, our simple model trained on a small dataset is not always able to provide well-calibrated posterior estimates. This is because the model was trained on a limited number of simulations with a small batch size and for a short duration. To improve the accuracy of the posterior estimates, it is necessary to train the model with a larger batch size (around 1024 or more) and for a longer period (around 50_000 training steps).
The Flux1 architecture is quite powerful and flexible, but being transformer based requires a longer training time and greatly benefits from larger datasets and large batch sizes to avoid overfitting the training dataset.
As an experiment, we retrained the model with a batch size of 1024 for 50_000 training steps, and obtained much better results in terms of posterior calibration. For reference, we provide the pre-trained model checkpoint and training configuration to load directly without retraining.
[49]:
# checkpoint_dir = os.path.join(os.getcwd(), "examples/getting_started/checkpoints")
# config_path = os.path.join(
# os.getcwd(), "examples/getting_started/config_flow_flux.yaml"
# )
# pipeline = Flux1FlowPipeline.init_pipeline_from_config(
# train_dataset_grain,
# val_dataset_grain,
# dim_obs,
# dim_cond,
# config_path,
# checkpoint_dir,
# )
# pipeline.restore_model(2)
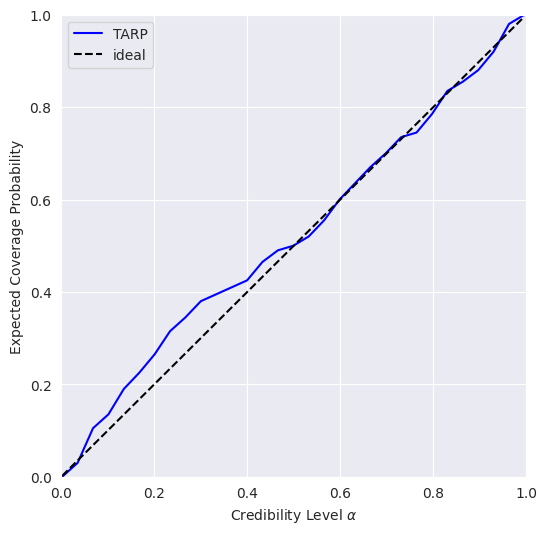
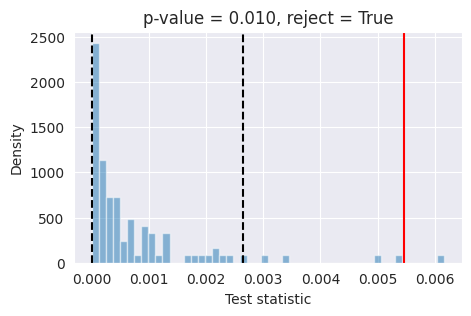
Now try running again the code for the posterior calibration tests, after loading the pre-trained model as shown above. You should get something like this, hinting to a much better calibrated model: