My First Model#
![]()
This guide will walk you through creating and training your first simulation-based inference model using GenSBI. We will cover the essential steps, from defining a simulator to training a neural density estimator.
As a first step, make sure GenSBI is installed in your environment. If you haven’t done so yet, please refer to the Installation Guide before proceeding, or simply run:
# step 1: install packages
# !uv pip install --quiet "gensbi[cuda12,examples]"
Next, it is convenient to download the GenSBI-examples package, which contains several example notebooks and checkpoints, including this one. You can do so by running:
# step 2: clone the examples repository
# !git clone --depth 1 https://github.com/aurelio-amerio/GenSBI-examples.git
# step 3: cd into the examples folder
# %cd GenSBI-examples/examples/getting_started/GenSBI-examples
# automatically install dependencies if using Colab
try: #check if we are using colab, if so install all the required software
import google.colab
colab=True
except:
colab=False
if colab: # you may have to restart the runtime after installing the packages
!uv pip install --quiet "gensbi[cuda12,examples]"
!git clone --depth 1 https://github.com/aurelio-amerio/GenSBI-examples
%cd GenSBI-examples/examples/getting_started
Important:
If you are using Colab, you may need to restart the runtime after installation to ensure all packages are properly loaded.
Import the necessary modules from GenSBI and other libraries. If you don’t have a GPU available, set JAX_PLATFORMS to “cpu” in the cell below, but note that training will be significantly slower.
If you encounter import errors after installing, restart the notebook kernel and re-run this cell.
import os
# Set JAX backend (use 'cuda' for GPU, 'cpu' otherwise)
os.environ["JAX_PLATFORMS"] = "cuda"
# os.environ["JAX_PLATFORMS"] = "cpu"
import grain
import numpy as np
import jax
from jax import numpy as jnp
from numpyro import distributions as dist
from flax import nnx
from gensbi.recipes import Flux1FlowPipeline
from gensbi.models import Flux1Params
from gensbi.utils.plotting import plot_marginals
import matplotlib.pyplot as plt
The simulator#
The first step in SBI is defining a simulator. The simulator takes input parameters \( heta\) and produces synthetic observations \(x\). For this tutorial, we use a simple simulator where the observation \(x\) is drawn from a Gaussian distribution centered at \( heta\).
The simulator takes in a parameter vector theta of size 3 and returns an observation vector xs of size 3.
In the context of posterior density estimation (Simulation-Based Inference), our goal is to infer the parameters theta given an observation xs. Therefore, theta is the target variable (what we want to predict the distribution of) and xs is the condition.
dim_obs = 3 # dimension of the observation (theta), that is the simulator input shape
dim_cond = 3 # dimension of the condition (xs), that is the simulator output shape
dim_joint = dim_obs + dim_cond # dimension of the joint (theta, xs), useful later
def _simulator(key, thetas):
xs = thetas + 1 + jax.random.normal(key, thetas.shape) * 0.1
thetas = thetas[..., None]
xs = xs[..., None]
# when making a dataset for the joint pipeline, thetas need to come first
data = jnp.concatenate([thetas, xs], axis=1)
return data
Next, we define a prior distribution \(p( heta)\), which represents our knowledge about the parameters before observing any data. Here, we use a Uniform prior.
theta_prior = dist.Uniform(
low=jnp.array([-2.0, -2.0, -2.0]), high=jnp.array([2.0, 2.0, 2.0])
)
For convenience, we define a wrapper function that handles both prior sampling and data generation in a single call.
def simulator(key, nsamples):
theta_key, sample_key = jax.random.split(key, 2)
thetas = theta_prior.sample(theta_key, (nsamples,))
return _simulator(sample_key, thetas)
The dataset#
We generate a training dataset by running the simulator multiple times. We sample parameters from the prior and then run the simulator for each parameter set. This dataset of \((\theta, x)\) pairs is used to train the neural density estimator.
GenSBI is designed to work with any dataset that provides an iterator yielding pairs of (parameters, observations).
However, for efficient training, especially with large datasets, we recommend using a high-performance data loader like grain to handle batching, shuffling, and prefetching.
# Define your training and validation datasets.
train_data = simulator(jax.random.PRNGKey(0), 100_000)
val_data = simulator(jax.random.PRNGKey(1), 2000)
# utility function to split data into observations and conditions
def split_obs_cond(data):
return data[:, :dim_obs], data[:, dim_obs:] # assuming first dim_obs are obs, last dim_cond are cond
We create a grain dataset with batch size = 256. The larger the batch size, the more stable the training.
Adjust according to your hardware capabilities, e.g. GPU memory (try experimenting with 256, 512, 1024, etc).
batch_size = 256
train_dataset_grain = (
grain.MapDataset.source(np.array(train_data))
.shuffle(42)
.repeat()
.to_iter_dataset()
.batch(batch_size)
.map(split_obs_cond)
.mp_prefetch() # If you use prefetching in a .py script, make sure your python script is thread safe, see https://docs.python.org/3/library/multiprocessing.html
)
val_dataset_grain = (
grain.MapDataset.source(np.array(val_data))
.shuffle(42)
.repeat()
.to_iter_dataset()
.batch(batch_size)
.map(split_obs_cond)
.mp_prefetch()
)
Because we called .repeat(), these dataloaders cycle through the data indefinitely, which is required for step-based training.
You can get samples from the dataset using:
iter_dataset = iter(train_dataset_grain)
obs,cond = next(iter_dataset) # returns a batch of (observations, conditions)
print(obs.shape, cond.shape) # should print (batch_size, dim_obs, 1), (batch_size, dim_cond, 1)
The Model#
We now set up the Neural Density Estimator. We use Flux1, a state-of-the-art transformer-based flow matching model. While this architecture is overkill for a simple Gaussian problem, we use it here to demonstrate the standard workflow for complex tasks.
# define the model parameters
params = Flux1Params(
in_channels=1, # each observation/condition feature has only one channel (the value itself)
vec_in_dim=None,
context_in_dim=1,
mlp_ratio=3, # default value
num_heads=4, # number of transformer heads
depth=4, # number of double-stream transformer blocks
depth_single_blocks=8, # number of single-stream transformer blocks
val_emb_dim=10, # Features per head for value embedding
id_emb_dim=4, # Features per head for ID embedding
qkv_bias=True, # default
dim_obs=dim_obs, # dimension of the observation (theta)
dim_cond=dim_cond, # dimension of the condition (xs)
id_merge_mode="concat",
id_embedding_strategy=("absolute", "absolute"),
rngs=nnx.Rngs(default=42), # random number generator seed
param_dtype=jnp.bfloat16, # data type of the model parameters. if bfloat16 is not available on your machine, use float32
)
# you can also try the "sum" embedding strategy, how does the performance of the model compare? Why? Hint: this is a low dimensional problem, with small axes_dim
# params = Flux1Params(
# in_channels=1, # each observation/condition feature has only one channel (the value itself)
# vec_in_dim=None,
# context_in_dim=1,
# mlp_ratio=3, # default value
# num_heads=2, # number of transformer heads
# depth=4, # number of double-stream transformer blocks
# depth_single_blocks=8, # number of single-stream transformer blocks
# axes_dim = [10], # Features per head for value embedding
# qkv_bias=True, # default
# dim_obs=dim_obs, # dimension of the observation (theta)
# dim_cond=dim_cond, # dimension of the condition (xs)
# id_merge_mode="sum",
# id_embedding_strategy=("absolute", "absolute"),
# rngs=nnx.Rngs(default=42), # random number generator seed
# param_dtype=jnp.bfloat16, # data type of the model parameters. if bfloat16 is not available on your machine, use float32
# )
Next, we configure the training hyperparameters. We start from the default training configuration and customize a few key settings:
checkpoint_dir = f"{os.getcwd()}/checkpoints"
training_config = Flux1FlowPipeline.get_default_training_config()
training_config["checkpoint_dir"] = checkpoint_dir
training_config["experiment_id"] = 1
training_config["nsteps"] = 10_000
training_config["decay_transition"] = 0.80
training_config["warmup_steps"] = 500
Note:
It is important to set the number of training steps (nsteps) in the training config, as this will ensure warmup steps and decay transition are computed correctly.
# Instantiate the pipeline
pipeline = Flux1FlowPipeline(
train_dataset_grain,
val_dataset_grain,
dim_obs,
dim_cond,
params=params,
training_config=training_config,
)
Training#
Now we train the model. The number of training steps was already set in the training configuration above. We only need to provide a random number generator for reproducibility.
rngs = nnx.Rngs(42)
# uncomment to train the model
# loss_history = pipeline.train(
# rngs, save_model=False
# ) # if you want to save the model, set save_model=True
Alternatively, you can skip training and load the pre-trained checkpoint provided with this example:
pipeline.restore_model(2) # we have stored the pretrained model with tag 2
# steps = np.linspace(1, len(loss_history[0]), len(loss_history[0]))*100
# plt.plot(steps, loss_history[0], label="train loss")
# plt.plot(steps, loss_history[1], label="val loss")
# plt.yscale("log")
# plt.xlabel("steps")
# plt.ylabel("loss")
# plt.ylim(0.1,10)
# plt.legend()
# plt.show()
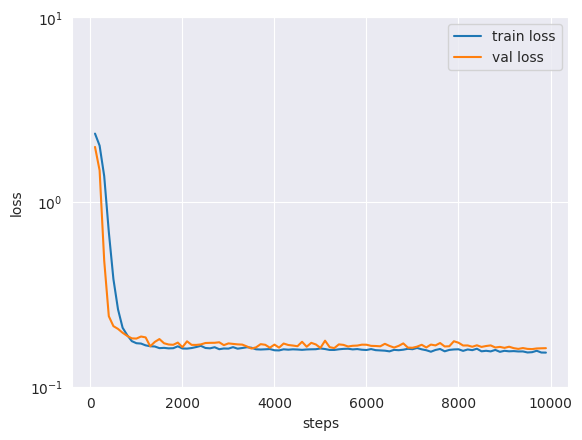
After the training is complete, by inspecting the loss curve we can see that the model has converged to a stable value for the train and validation loss.
Note that, unlike traditional tasks, flow and diffusion models keep “learning” even when the loss function seems to have stabilized. As such, even though the loss function seems to have stabilized after the scheduled training steps, it is often beneficial to keep training the model for longer.
Flow and diffusion models are less likely to overfit the training data, given their stochastic nature. Nonetheless, if the model is excessively over-parameterized, and not enough training data is provided, artifacts in the posteriors may appear in the form of “spikes”. On the other hand, if the model is under-parameterized, the posterior may be excessively smooth, or underconfident.
Sampling from the posterior#
Once the model is trained, we can estimate the posterior distribution for any new observation. We pass the observed data to the pipeline’s sample method, which draws samples from the learned posterior.
new_sample = simulator(jax.random.PRNGKey(20), 1) # generate one (theta, x) pair
true_theta = new_sample[:, :dim_obs, :] # the true parameters used for the simulation
x_o = new_sample[:, dim_obs:, :] # the observed data, which we condition on
Now we sample from the posterior:
samples = pipeline.sample(rngs.sample(), x_o, nsamples=100_000)
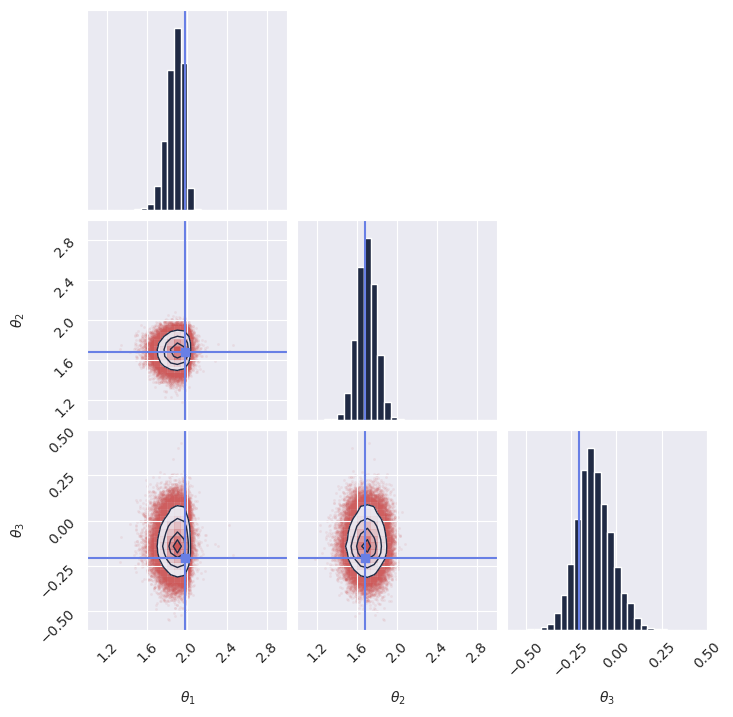
Once we have the samples, we display the marginal distributions:
plot_marginals(
np.array(samples[..., 0]), gridsize=30, true_param=np.array(true_theta[0, :, 0]), range = [(1, 3), (1, 3), (-0.6, 0.5)]
)
# plt.savefig("flux1_flow_pipeline_marginals.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
Computing the log_prob exactly#
GenSBI can also be used to compute the exact value of the (approximate) posterior log_prob at a given point. This method requires an ODE fomulation, and is currently implemented for Flow Matching models according to the standard ODE implementation, and for Score Matching models using the probability flow ODE formulation.
GenSBI - and diffusion/flow models in general - is optimized for sampling, and evaluating the log_prob exactly is computationally expensive, as it involves solving a coupled ODE involving the divergence of the vector field.
from gensbi.utils.plotting import _plot_2d_dist_contour
new_sample = simulator(jax.random.PRNGKey(20), 1) # generate one (theta, x) pair
true_theta = new_sample[:, :dim_obs, :] # the true parameters used for the simulation
x_o = new_sample[:, dim_obs:, :] # the observed data, which we condition on
You can compute the value of the posterior log_prob at one point using a convenience function from the pipeline:
x_1 = jnp.array([1.9, 1.7, -0.1]).reshape((1,-1,1))
pipeline.log_prob(x_1, x_o, use_ema=True) # Array([4.342539], dtype=float32)
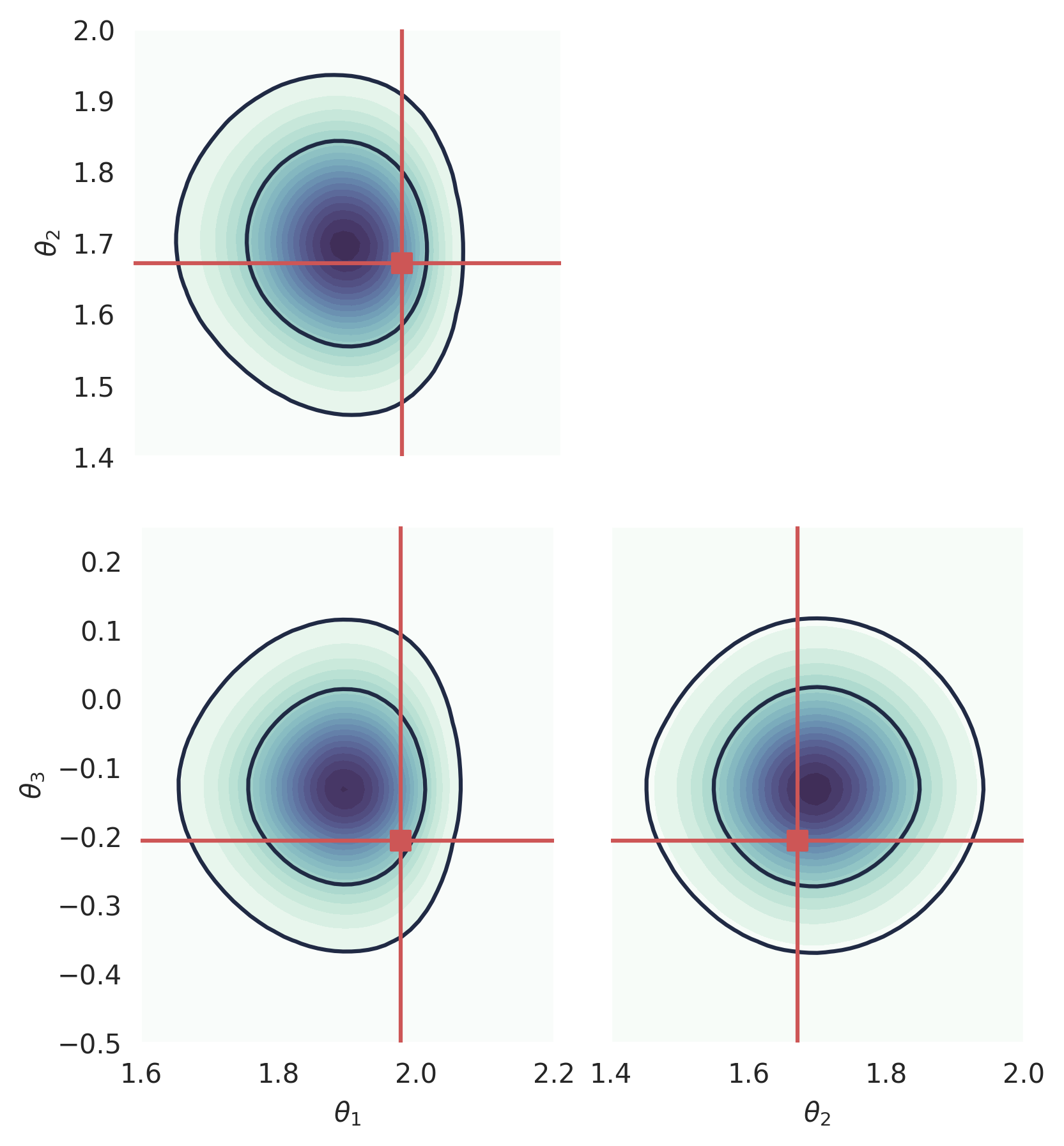
We can use this to plot the log_prob in a corner plot. Note that, at the moment, computing 2D marginals is not fast for GenSBI, as it involves marginalizing the full ND pdf.
# we create a 3D meshgrid
theta1 = np.linspace(1.6,2.2, 50)
theta2 = np.linspace(1.4,2.0, 51)
theta3 = np.linspace(-0.5,0.25, 52)
tt1, tt2, tt3 = jnp.meshgrid(theta1, theta2, theta3, indexing='ij')
tt1_flat = tt1.ravel()
tt2_flat = tt2.ravel()
tt3_flat = tt3.ravel()
x_1 = jnp.stack([tt1_flat, tt2_flat, tt3_flat], axis=-1)[...,None]
logp = pipeline.log_prob(x_1, x_o, use_ema=True)
# we can also compute the log_prob using the Hutchinson's divergence approximation
# key=jax.random.PRNGKey(42)
# logp_2 = pipeline.log_prob(x_1, x_o, use_ema=True, key=key, exact_divergence=False)
prob = jnp.exp(logp).reshape((len(theta1),len(theta2),len(theta3)))
# prob2 = jnp.exp(logp_2).reshape((len(theta1),len(theta2),len(theta3)))
# integrate one dimension out, to get 2D marginal distributions
prob12 = jnp.trapezoid(prob, x=theta3, axis=2)
prob13 = jnp.trapezoid(prob, x=theta2, axis=1)
prob23 = jnp.trapezoid(prob, x=theta1, axis=0)
fig, axes = plt.subplots(2,2, figsize=(6,6))
fontsize=12
ax = axes[1,0]
_plot_2d_dist_contour(theta1,theta3, prob13.T, ax=ax, true_param=[true_theta[:,0],true_theta[:,2]])
ax.set_xlabel(r"$\theta_1$")
ax.set_ylabel(r"$\theta_3$")
ax = axes[1,1]
_plot_2d_dist_contour(theta2,theta3, prob23.T, ax=ax, true_param=[true_theta[:,1],true_theta[:,2]])
ax.set_xlabel(r"$\theta_2$")
ax.set_ylabel("")
ax.set_yticks([])
ax = axes[0,0]
_plot_2d_dist_contour(theta1,theta2, prob12.T, ax=ax, true_param=[true_theta[:,0],true_theta[:,1]])
ax.set_xlabel("")
ax.set_xticks([])
ax.set_ylabel(r"$\theta_2$")
axes[0, 1].set_visible(False)
fig.subplots_adjust(
hspace=0.05, wspace=0.1, left=0.2, right=0.98, top=0.98, bottom=0.06
)
for ax in axes.ravel():
ax.set_aspect("equal", adjustable="box")
plt.savefig("flux1_flow_pipeline_log_prob.png", dpi=300, bbox_inches="tight") # uncomment to save the figure
plt.show()
Next steps#
Congratulations! You have successfully created and trained your first simulation-based inference model using GenSBI. You can now experiment with different simulators, priors, and neural density estimators to explore more complex inference tasks.
For more examples, please refer to the Examples Section of the GenSBI documentation.
As a next step, you might want to explore how to validate the performance of your trained model using techniques such as simulation-based calibration (SBC) or coverage plots. These methods help assess the quality of the inferred posterior distributions and ensure that your model is providing accurate uncertainty estimates.
Posterior calibration tests#
In this section, we perform posterior calibration tests using Simulation-Based Calibration (SBC), Targeted At Random Parameters (TARP) and L-C2ST methods to evaluate the quality of our trained model’s posterior estimates.
For a full overview of posterior calibration tests, refer to the sbi documentation.
# imports
from gensbi.diagnostics import check_tarp, run_tarp, plot_tarp
from gensbi.diagnostics import check_sbc, run_sbc, sbc_rank_plot
from gensbi.diagnostics import LC2ST, plot_lc2st
We sample 200 new observations from the simulator to perform the calibration tests. It is crucial that we use a seed different from the one used during training to avoid biased results.
key = jax.random.PRNGKey(1234)
# sample the dataset
test_data_ = simulator(jax.random.PRNGKey(1), 200)
# split in thetas and xs
thetas_ = test_data[:, :dim_obs, :] # (200, 3, 1)
xs_ = test_data[:, dim_obs:, :] # (200, 3, 1)
# sample the posterior for each observation in xs_
posterior_samples_ = pipeline.sample_batched(jax.random.PRNGKey(0), xs_, nsamples=1000) # (1000, 200, 3, 1)
For the sake of posterior calibration tests, the last two dimensions need to be flattened into a single dimension.
thetas = thetas_.reshape(thetas_.shape[0], -1) # (200, 3)
xs = xs_.reshape(xs_.shape[0], -1) # (200, 3)
posterior_samples = posterior_samples_.reshape(posterior_samples_.shape[0], posterior_samples_.shape[1], -1) # (1000, 200, 3)
SBC#
SBC checks whether the individual marginal posteriors are well-calibrated on average across many observations. It can reveal if the posteriors are systematically too narrow, too wide, or skewed.
ranks, dap_samples = run_sbc(thetas, xs, posterior_samples)
check_stats = check_sbc(ranks, thetas, dap_samples, 1_000)
print(check_stats)
f, ax = sbc_rank_plot(ranks, 1_000, plot_type="hist", num_bins=20)
plt.savefig("flux1_flow_pipeline_sbc.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
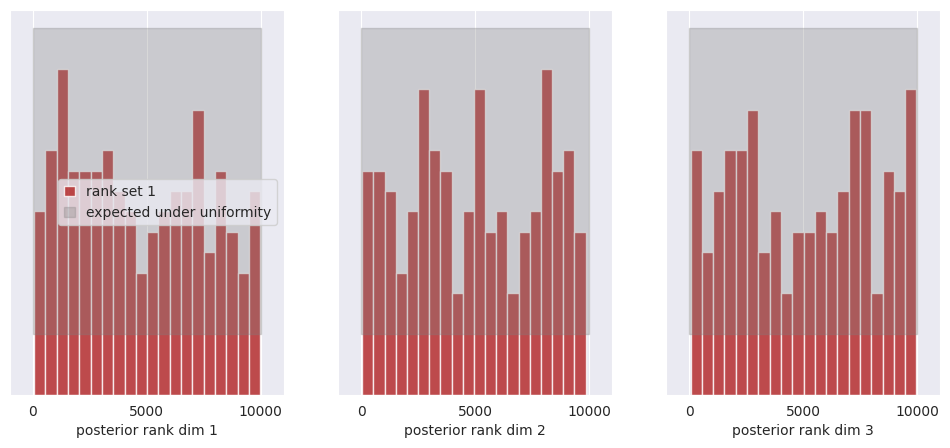
All of the bars fall within the confidence intervals of the uniform distribution, thus we cannot reject the hypothesis that the posterior marginals are calibrated.
See the SBI tutorial https://sbi.readthedocs.io/en/latest/how_to_guide/16_sbc.html for more details on SBC.
Marginal posteriors credibility test#
The (marginal) credibility test is a statistical test that checks if the model’s posterior distribution is consistent with the observed data. In particular, it evaluates if the true parameter values are within the credible region of the posterior distribution. This test can be used to identify if the marginal posterior distribution in a specific dimension is over or under confident.
alpha_marginal = compute_marginal_coverage(
thetas, posterior_samples, method="histogram"
)
plot_marginal_coverage(alpha_marginal)
plt.savefig(
"flux1_flow_pipeline_marginal_coverage.png", dpi=100, bbox_inches="tight"
) # uncomment to save the figure
plt.show()
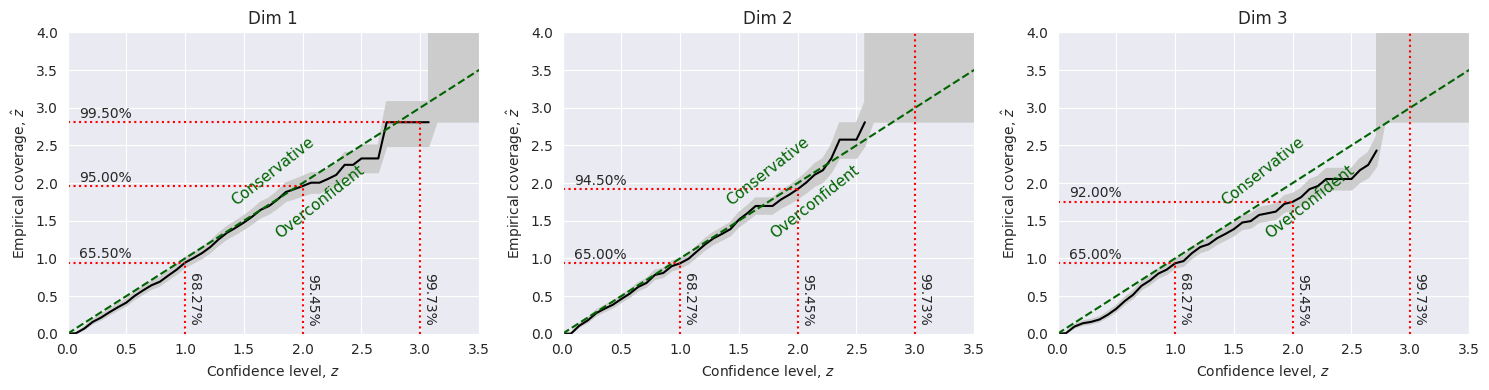
From this test, it turns out that the model posterior distribution is slightly overconfident in the first dimension. It is well calibrated in the second dimension, and it is overconfident in the third dimension.
TARP#
TARP is an alternative calibration check that evaluates the joint posterior (not just individual marginals). See Lemos et al. (2023) for details.
tarp_results = run_tarp(
thetas,
posterior_samples,
references=None, # will be calculated automatically.
)
atc, ks_pval = check_tarp(tarp_results)
print(atc, "Should be close to 0")
print(ks_pval, "Should be larger than 0.05")
plot_tarp(tarp_results)
plt.savefig("flux1_flow_pipeline_tarp.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
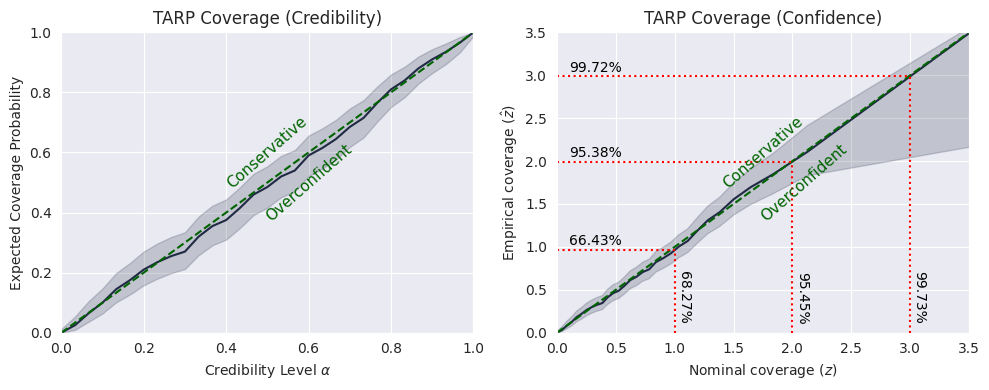
If the black curve is above the diagonal, then the posterior estimate is under-confident. If it is under the diagonal, then the posterior estimate is over-confident.
While the curve does not coincide exactly with the diagonal, from the TARP test we cannot reject the hypothesis that the model is properly calibrated.
See https://sbi.readthedocs.io/en/latest/how_to_guide/17_tarp.html for more details on TARP.
L-C2ST#
Unlike SBC and TARP, which evaluate average calibration across many observations, L-C2ST tests whether the posterior is accurate for a specific observation. This makes it useful for diagnosing local failures.
# Simulate calibration data. Should be at least in the thousands.
key = jax.random.PRNGKey(1234)
# sample the dataset
test_data = simulator(jax.random.PRNGKey(1), 10_000)
# split in thetas and xs
thetas_ = test_data[:, :dim_obs, :] # (10_000, 3, 1)
xs_ = test_data[:, dim_obs:, :] # (10_000, 3, 1)
# Generate one posterior sample for every prior predictive.
posterior_samples_ = pipeline.sample(key, x_o=xs_, nsamples=xs_.shape[0])
thetas = thetas_.reshape(thetas_.shape[0], -1) # (10_000, 3)
xs = xs_.reshape(xs_.shape[0], -1) # (10_000, 3)
posterior_samples = posterior_samples_.reshape(posterior_samples_.shape[0], -1) # (10_000, 3)
from gensbi.diagnostics import LC2ST, plot_lc2st
# Train the L-C2ST classifier.
lc2st = LC2ST(
thetas=thetas,
xs=xs,
posterior_samples=posterior_samples,
classifier="mlp",
num_ensemble=1,
)
_ = lc2st.train_under_null_hypothesis()
_ = lc2st.train_on_observed_data()
key = jax.random.PRNGKey(12345)
sample = simulator(key, 1)
# theta_true_ = sample[:, :dim_obs, :]
x_o_ = sample[:, dim_obs:, :]
# Note: x_o must have a batch-dimension. I.e. `x_o.shape == (1, observation_shape)`.
post_samples_star_ = pipeline.sample(key, x_o_, nsamples=10_000)
# theta_true = theta_true_.reshape(-1) # (3,)
x_o = x_o_.reshape(1,-1) # (3,)
post_samples_star = np.array(post_samples_star_.reshape(post_samples_star_.shape[0], -1)) # (10_000, 3)
post_samples_star.shape, x_o.shape
fig,ax = plot_lc2st(
lc2st,
post_samples_star,
x_o,
)
plt.savefig("flux1_flow_pipeline_lc2st.png", dpi=100, bbox_inches="tight") # uncomment to save the figure
plt.show()
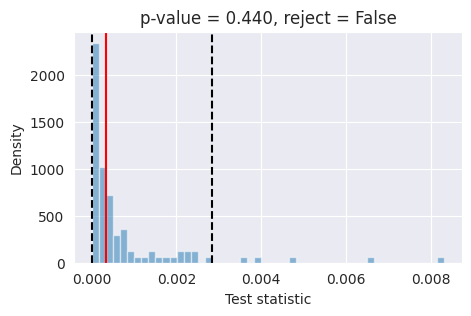
If the red bar falls outside the two dashed black lines, it indicates that the model’s posterior estimates are not well-calibrated at the 95% confidence level and further investigation is required.
For the specific chosen observation, the model seems to be properly calibrated.
Conclusions#
Based on SBC, Marginal coverage,TARP, and L-C2ST, all calibration tests are consistent with a mostly well-calibrated posterior. We cannot reject the hypothesis that the model is properly calibrated.